LINQ was a major part of the release of .Net Framework 3.5, and has since been one of the most powerful features of the C# standard libraries.
Part of LINQ’s usefulness comes from the clarity that it can give to complex code handling collections.
In fact, it is not only useful for programs where one would classically use queries – like database applications – but can be used in a variety of ways in almost any application, including games. The most common use cases of LINQ deal with selecting, converting, combining and returning items from collections in clearly defined and deterministic way.

When it comes to selecting items from collections, many games have additional requirements not covered by LINQ.
One of them is randomness. We often need to:
- select a random element from a set;
- select a subset of elements from a set;
- or shuffle an ordered collection.
In this post we will construct methods for exactly these purposes, using the same extension method style of LINQ.
Since we care about the quality of our code, we will attempt to find solutions that are:
- uniformly distributed;
- and optimal in time and space complexity.
We will not prove our algorithms’ complexity. However, the examples below will be very straight forward.
Uniform distribution may be less clear and we will sketch a proof for the simplest of our algorithms using induction. The same approach can be used to show the uniform distribution of all our examples below.
All code contained in this post – including several small improvements – can be found in Bearded.Utilities, the open source C# utilities library I am working on with Tom Rijnbeek.
Random element
In the simplest case we want to select a random item from a collection. For the purpose of this post we will assume that all items should have the same likelihood to be chosen. Differing probabilities can be easily implemented, but that is a topic for a different post.
The signature for the method we are going to write is very straight forward:
public static T RandomElement<T>(this IEnumerable<T> source, Random random)
The reason we give the method a Random object is so that we have control over which is used. In specific implementations, a static random could also be used, though thread-safety would have to be taken into account (the Random class is not thread-safe).
While we allow this extension method to be called on any IEnumerable, there are a few cases where our implementation is almost trivial.
Simple cases
When we are given a sequence that implements IList we can use the following code to select our random element:
var asList = source as IList<T>;
if (asList != null)
return asList[random.Next(asList.Count)];
As you can see we use the lists Count property to find a valid random index in constant time and return the item with that index.
In fact, we can weaken this constraint. ICollection also has a Count property, and we can use LINQ’s ElementAt extension method to select the element at our randomly determined position in the sequence. That method is implemented efficiently, and we can rely on it using the fastest way it can to get the element at the given index.
var asCollection = source as ICollection<T>;
if (asCollection != null)
return asCollection.ElementAt(random.Next(asCollection.Count));
In these two cases – where the first is a strict sub-case of the second – uniform distribution is trivial.
That is, as long as we assume the uniformity of Random.Next(). This is in fact specified to be the case by the documentation. We will assume this property for the sake of this post.
However, it is fair to mention at this point that concerns have been raised about the implementation of the Random class which may influence the quality of the generated random numbers.
The general case
Unfortunately we do not always know the size of our collection ahead of time.
If that is the case, there are two solutions. We can either enumerate the sequence to a list using LINQ’s ToList, or we can enumerate the sequence and somehow extract an element at a random position while doing so.
Using ToList is by far the simpler solution. However, the method allocates a lot (O(n)) of memory for which we really have no use.
We will instead go the second route and use induction to create an algorithm that fulfils our requirements of uniformity.
In the trivial case of a collection of size one, we select the single element and return it. If our collection is of size two, each element is returned with probability p = 1/2. In the general case of size n, we have p = 1/n.
Assuming we have a list of size n and a random element from it, we perform an inductive step as follows:
- We add an element to the list and choose it as our selected element with probability
p = 1/(n + 1).
Since the list now has size n + 1, this element has the correct probability.
All the remaining elements had the probability of p = 1/n before. We have to multiply this with the probability that we did not choose a new element, which is p = 1 - 1/(n + 1).
We solve the equation as follows:
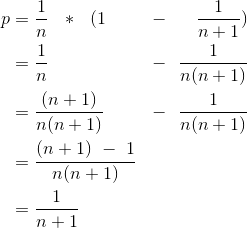
You can also find a LaTeX and a plain text version of this equation here.
As we can see, this inductive step also provides us with the correct probability for our previous elements.
By induction, we can use this algorithm to uniformly select a random item from a sequence of arbitrary length.
The code for this looks as follows:
T current = default(T);
int n = 0;
foreach (T element in source)
{
n++;
if (random.Next(n) == 0)
current = element;
}
return current;
Note that Random.Next(1) will always return zero, so that the first element is always selected.
While this general case still uses only constant space, it does run in O(n) time, which cannot be avoided if the size of the input is unknown.
Random subset
Our second extension method will select a random subset from a given collection. The method’s signature is as follows:
public static IEnumerable<T> RandomSubset<T>(this IEnumerable<T> source, int k, Random random)
k here is the size of the subset to select.
If k is equal to ‘n’, the size of the source collection, we return the entire collection. Otherwise, and in general, each element is returned with p = k/n.
Again, we use induction to create our algorithm:
- We keep a list of
kelements, filled with our current subset. - This list is initialised with the first
kelements of the collection. - We then enumerate the remaining elements and select them with the correct probability for the solution of the current sub-problem.
- Each element so selected is inserted at a random position in our subset list, replacing one of the previous items.
We will not show uniformity as above, however the equations are similar.
This can be implemented as follows:
var set = new T[k];
int n = 0;
foreach (var element in source)
{
// copy first 'k' elements
if (n < k)
set[d] = element;
else
{
// add others with decreasing likelyhood
int index = random.Next(n + 1);
if (index < k)
set[index] = element;
}
n++;
}
Note that for k = 1 this code is exactly equivalent to the previous snippet selecting a single element.
The runtime of this algorithm is O(n) and it uses O(k) space, which is very good, and – I believe – optimal.
An alternative with additional constraints
However, there is a way we can optimise the algorithm by adding additional constraints:
- The input collection needs to have direct access and known length, meaning that it implements
IList. - We need to be allowed to modify the input collection.
Given these special cases we can make the algorithm run in O(k) time, and have it use only constant additional space, which is a great improvements.
The reason I would not advocate this approach however is the second constraint. Certainly as a LINQ style extension method, we should never modify our source collection.
We could circumvent the second constraint by copying our input list. However that would not only raise our runtime back to O(n), but it would also require O(n) space, making it have worse complexity than our previous algorithm.
For completeness – and those cases where these requirements can be fulfilled and performance is of the essence – this algorithm works as follows:
- Select a random element from the list and switch it with the first element.
- Select a random element from the list, excluding the first element, and switch it with the second element.
- Proceed the same, fixing one element each step, until
kelements are fixed. - Return the k first elements of the list.
The implementation might look like this:
for (int n = 0; n < k; n++)
{
int i = random.Next(n, list.Count);
T temp = list[i];
list[i] = list[n];
list[n] = temp;
}
return list.Take(k);
Note that if we do not need to access the source list again after this call, we could make this method use deferred execution.
This would be achieved by returning each randomly selected element using the yield return statement after the switch.
Under certain circumstances – namely large input lists and slow or delayed iteration of the random subset – this may be a desired property.
Shuffle collection
If we look at the previously described methods for selecting a random subset, we see that if we ask it to return a subset with the same length as the input, it return the entire list.
The first method would do so in the same order as the input, which is hardly useful.
The second method however would return our list in a random order, since it selects and swaps random elements while iterating the list.
In fact, this is one of the fastest ways of shuffling a list, and its runtime of O(n) and only constant space usage are trivially optimal, since they correspond to the complexity of the algorithm’s output.
The code can then be slightly simplified to the following methods:
public static void Shuffle<T>(this IList<T> list, Random random)
{
for (int n = 0; n < list.Count; n++)
{
int i = random.Next(n, list.Count);
T temp = list[i];
list[i] = list[n];
list[n] = temp;
}
}
public static List<T> Shuffled<T>(this IEnumerable<T> source, Random random)
{
var list = source.ToList();
list.Shuffle(random);
return list;
}
If we do not have list in the first place, or do not want to change our original one, we still need to copy or enumerate our sequence into a new list. However, this does not increase our runtime, and adds only an additional space complexity of O(n), which is again optimal.
For completeness, here is a deferred version of the Shuffled method:
public static IEnumerable<T> ShuffledDeferred<T>(this IEnumerable<T> source, Random random)
{
var list = source.ToList();
for (int n = 0; n < list.Count; n++)
{
int i = random.Next(n, list.Count);
yield return list[i];
list[i] = list[n];
}
}
Note that even though it shuffles and returns values only when needed, it still needs to enumerate them to a list beforehand since we rely on the length of the list and have to use it as internal storage to guarantee uniform distribution.
The shuffling algorithm just discussed is a slight variant on the popular Fisher–Yates shuffle.
The difference between the algorithms is that Fisher-Yates fixes elements starting from the back of the list, instead of starting in the front. This difference is insignificant, but I find iteration in this order to be more intuitive.
For a great visualisation of the Fisher-Yates shuffle – as well as more information about it, and shuffling in general – take a look at this post by Mike Bostock (all the way at the end of the post).
Conclusion
Above we constructed LINQ style extension methods to allow us to select random elements and subsets from collections, as well as shuffle them.
While not conclusively proven in this text, the presented algorithms all return uniformly distributed results.
Further, they also have optimal runtime given their constraints.
If you are interested in using these methods, please take a look at my full implementation in Bearded.Utilities.
Those implementations treat several special cases not discussed above and have been documented, tested and optimised.
The class also contains a number of other useful extension methods to supplement LINQ.
I hope you found this post informative. If so, or if you have any other comment or question, feel free to leave a comment below.
Until next time, enjoy the pixels!
| Reference: | Random elements, subsets and shuffling collections – LINQ style from our NCG partner Paul Scharf at the GameDev<T> blog. |