Abstract
In this article, excerpted from my upcoming book
Microservices in .NET, I will talk about the characteristics that help you recognize a Microservice when you see one and that help you scope and implement your services in way that enable the benefits of Microservices
A Microservice is a service with one and only one very narrowly focused capability. That capability is exposed to the rest of the system in a remote API. For example, think of a system for managing a warehouse: Some capabilities that might each be provided by a Microservice in such a system are:
- Receive stock
- Calculate where new stock should be stored
- Calculate placement routes inside the warehouse for putting stock into the right storage units
- Assign placement routes to warehouse employees
- Receive orders
- Calculate pick routes in the warehouse given a set of orders
- Assign pick routes to warehouse employees
Each of these capabilities – and most likely many more – are implemented by individual Microservices. Each Microservice runs in separate processes and can be deployed on its own independently of the other Microservices. Likewise, each Microservice has its own dedicated database. Still each Microservice collaborates and communicates with other Microservices.
It is entirely possible that different Microservices within a system will be implemented on different platforms – some Microservices may be on .NET, others on Erlang, and still others on Node.js. As long as they can communicate in order to collaborate this polyglot approach can work out fine. HTTP is a good candidate for the communication: All the mentioned platforms, as well as many others, can handle HTTP nicely. Other technologies also fit the bill for Microservice communication: Some queues, some service buses and some binary protocols for instance. Of these HTTP is probably the most widely supported, is fairly easy to understand and – as illustrated by the World Wide Web – is quite capable, all in all making it a good candidate.
To illustrate, think of the warehouse system again. One Microservice in that system is the Assign Pick Routes Microservices. Figure 1 shows the Assign Pick Route Microservice receiving a request from another collaborating Microservice. The request is for the next pick route for a given employee. The Assign Pick Route Microservice has to find a suitable route for the employee. Calculating an optimal route is done in another Microservice. The Assign Pick Route Microservice simply gets notified of the pick routes and only needs to decide how to assign them to employees. When a request for a pick route for a given employee comes in the Assign Pick Route Microservice looks in its database for a suitable pick route, selects one and returns it to the calling Microservice.
 |
| Figure 1 The Assign Pick Route Microservice exposes an API for getting a pick route for an employee. Other Microservices can call that API. |
What is a Microservices Architecture?
Microservices as an architectural style is a lightweight form of Service Oriented Architecture where the services are very tightly focused on doing one thing and doing it well.
A system that uses Microservices as its main architectural style is a distributed system of a – most likely large – number of collaborating Microservices. Each Microservice runs on its own in its own process. Each Microservice only provides a small piece of the picture and the system as a whole works because the Microservices collaborate closely. To collaborate they communicate over a lightweight medium that is not tied to one specific platform like .NET, Java or Erlang. As mentioned, all communication between Microservices, in this book, is over HTTP, but other options include a queue, a bus or a binary protocol like Thrift.
The Microservices architectural style is quickly gaining in popularity for building and maintaining complex server side software systems. Understandably so: Microservices offer a number of potential benefits over both more traditional service oriented approaches and monolithic architectures. Microservices – when done well – are malleable, scalable, resilient and allow a short lead time from start of implementation to deployment to production. A combination which often prove evasive for complex software system.
Microservice Characteristics
So far I have established that a Microservice is a very tightly focused service, but that is still a vague definition. To narrow down the definition of what a Microservice is, let’s take a look at what characterizes a Microservice. In my interpretation of the term, a Microservice is characterized by being:
- Responsible for one single capability
- Individually deployable
- Consists of one or more processes
- Owns its own data store
- A small team can maintain a handful of Microservices
- Replaceable
This list of characteristics both helps you recognize a Microservice when you see one and helps you scope and implement your services in way that enable the benefits of Microservices – a malleable, scalable and resilient system. Let’s look at each in turn.
Responsible for One Single Capability
A Microservice is responsible for one and only one capability in the overall system. Breaking that statement down there are two parts in there: First, a Microservice has a single responsibility. Second, that responsibility is for a capability. The single responsibility principle has been stated in several ways. One traditional way is:
“There should never be more than one reason for a class to change.”
— Robert C. Martin SRP: Single Responsibility Principle
While this way of putting it specifically mentions “a class” the principle turns out to apply on other levels than that of a class in an object-oriented language. With Microservices, we apply the single responsibility principle at the level of services. Another, newer, way of stating the single responsibility principle, also from Uncle Bob, is:
“Gather together the things that change for the same reasons. Separate those things that change for different reasons.”
— Robert C. Martin The Single Responsibility
This way of stating the principle applies to Microservices: A Microservice should implement exactly one capability. That way the Microservice will have to change only when there is a change to that capability. Furthermore, we should strive to have the Microservice fully implement the capability, such only that one Microservice has to change when the capability is changed.
A capability in Microservice system can mean a couple of things. Primarily, a capability can be a business capability. A business capability is something the system does that contributes to purpose of the system – like keeping track of users shopping carts or calculating prices. A very good way to tease apart which separate business capabilities a system has is to use Domain Driven Design. Secondly, a capability can sometimes be a technical capability that several other Microservices need to make use of – integration to some third-party system for instance. Technical capabilities are not the main drivers for breaking down a system to Microservices, they are only identified as the result of several of Microservices implementing business capabilities needing the same technical capability.
Individually Deployable
Every Microservice should be individually deployable. That is: When you a change a particular Microservice you should be able to deploy that change of the Microservice to the production environment without deploying or in any other way touching any other part of your system. In fact, the other Microservices in the system should continue running and working during the deployment of the changed Microservice as well as after that new version is deployed and up and running.
Consider an ecommerce site. Whenever a change is made to the Shopping Cart Microservice, you should be able to deploy just the Shopping Cart Microservice. Meanwhile the Price Calculation Microservice, the Recommendation Microservice, the Product Catalog Microservice etc. should continue working and serving user requests.
Being able to deploy each Microservice individually is important for several reasons. For one, in a Microservice system, there are many Microservices and each one will collaborate with several others. At the same time development work is done on all or many of the Microservices in parallel. If we have to deploy all or groups of them in lock step, managing the deployments will quickly become unwieldy typically resulting in infrequent, but big risky deployments. This is something we very much want to avoid. Instead, we want to be able to deploy small changes to each Microservice often resulting in frequent and small low risk deployments.
To be able to deploy a single Microservice while the rest of the system continues to function, the build process must be set up with this in mind: Each Microservice has to be built into separate artifacts or packages. Likewise, the deployment process itself must also be set up to support deploying Microservices individually while other Microservices continue running. For instance, a rolling deployment process where the Microservice is deployed to one server at a time in order to reduce downtime can be used.
The way Microservices interact is also informed by the fact that we want to deploy them individually. Changes to the interface of a Microservice must be backwards-compatible in the majority of cases, so that other existing Microservices can continue to collaborate with the new version the same way they did with the old one. Furthermore, the way Microservices interact must be resilient in the sense that each Microservices must expect the other services to fail once in a while and continue working as best it can anyway. One Microservices failing – for instance because of a short period of downtime during deployment – must not result in other Microservices failing, only in reduced functionality or in slightly longer processing time.
Consisting of One or More Processes
A Microservice is made up of one or more processes. There are two sides to this characteristic. First, each Microservice runs in separate processes from the other Microservices. Second, each Microservice can have more than one process.
That Microservices run in separate processes is a consequence of wanting to keep each Microservice as independent of the other Microservices as possible. Furthermore, in order to deploy a Microservice individually, that Microservice cannot run in the same process as any other Microservice. Consider a Shopping Cart Microservice again. If it ran inside the same process as a Product Catalog Microservice, the Shopping Cart code might have a side effect on the Product Catalog. That would mean a tight and, undesirable coupling between the Shopping Car Microservice and the Product Catalog Microservice.
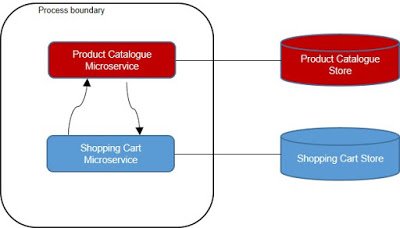 |
| Figure 2 Running more than one Microservice within a process leads to high coupling in terms of deployment. If two Microservices share the same process, deploying one will directly affect the other and may cause downtime or bugs in that one. |
Now consider deploying a new version of the Shopping Cart Microservice. We either would have to redeploy the Product Catalog Microservice too, or would have some sort of dynamic code loading capable of switching out the Shopping Cart code in the running process. The former option goes directly against Microservices being individually deployable. The second option is complex and at the very least puts the Product Catalog Microservice at risk of going down because of a deployment to the Shopping Cart Microservice.
Each Microservice may consist of more than one process. On the surface this may be surprising. We are, after all, trying to make each Microservice as simple to handle as possible, so why introduce the complexity of having more than one process? Let’s consider a Recommendation Microservice in an e-commerce site. It implements the recommendation algorithms that drive recommendations at our e-commerce site. These algorithms run in a process belonging to the Microservice. It also stores the data needed to provide a recommendation. This data could be stored in files on disk, but is more likely stored in a database. That database runs in a second process that also belongs to the Microservice. The need for a Microservice to often have two or more processes comes from the Microservice implementing everything needed to provide a capability including, for example, data storage and possibly background processing.
Owns Its Own Data Store
A Microservice owns the data store where it stores the data it needs. This is another consequence of wanting the scope of a Microservice to be a complete capability. For most business capabilities, some data storage is needed. For a Product Catalog Microservice, for instance, information about each product needs to be stored. To keep the Product Catalog Microservice loosely coupled with other Microservices, the data store containing the product information is completely owned by the Product Catalog Microservice. It is a decision of the Product Catalog Microservice how and when the product information is stored. Other Microservices – the Shopping Cart Microservice for instance – can only access product information through the interface to the Product Catalog Microservice, never directly from the Product Catalog Store.
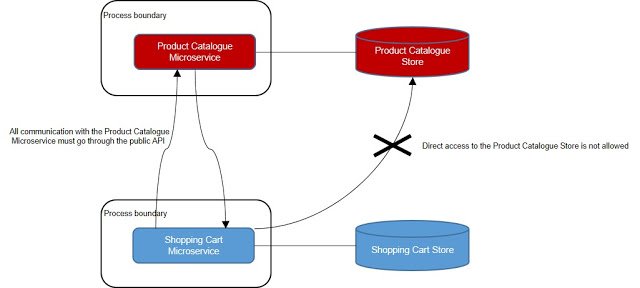 |
| Figure 3 One Microservice cannot access another’s data store. All communication with a given Microservice happens through its public API; only the Microservice itself is allowed to access its data store directly |
Each Microservice owning its own data store opens up the possibility for using different database technologies for different Microservices depending on the needs of each Microservice. The Product Catalog Microservice might use SQL Server to store product information, while the Shopping Cart Microservice might store each user’s shopping cart in Redis and the Recommendations Microservice could use an Elastic Search index to provide recommendations. The database technology chosen for a Microservice is part of the implementation and is hidden from the view of other Microservices. Mixing and matching database technologies with the requirements for each Microservice has the upside of allowing each Microservice to use exactly the database best suited for the job. This can have benefits in terms of development time, performance and scalability, but also comes with a cost. Databases tend to be complicated pieces of technology and learning to use and run one reliably in production is not easy. When choosing database technology for a Microservice, you should consider this trade-off. But also remember that since the Microservice owns its own data store, swapping it out for another database later is feasible.
Maintained by a Small Tema
So far, I have not talked much about the size of a Microservice even though the “micro” part of the term Microservice indicates that they are small. I do not believe, however, that it makes sense to discuss the number of lines of code that a Microservice should have, or the number of requirements, use cases or function points it should implement. All of that depends on the complexity of the capability provided by the Microservice. What makes sense, however, is to consider the amount of work involved in maintaining the Microservice. A rule of thumb that can guide the size of Microservice is that a small team – of, say, 5 people – should be able to maintain a handful or more Microservices. Maintaining a Microservice includes all aspects of keeping it healthy and fit for purpose: Developing new functionality, factoring out new Microservices from ones that have grown too big, running it in production, monitoring it, testing it, fixing bugs and everything else needed. Considering that a small team should be able to perform all of this for a handful of Microservices should give you an idea of the size of a typical Microservice.
Replaceable
That a Microservice is replaceable means it can be rewritten from scratch within a reasonable time frame. In other words, the team maintaining the Microservice can decide to replace the current implementation with a completely new implementation and do so within the normal pace of their work. This characteristic is another constraint on the size of a Microservice: If a Microservice grows too large it will be expensive to replace, only when kept small is it realistic to rewrite.
Why would a team decide to rewrite a Microservice? One reason could be that the code has become a mess. Another is that the Microservice doesn’t perform well enough in production.While these are not desirable situations, they can present themselves. Even if we are diligent while building our Microservices, changes in requirements over time can push the current implementation in ways it cannot handle. Over time, the code can become messy because the original design is bent too much. The performance requirements may increase too much for the current design to handle. If the Microservice is small enough to be rewritten within a reasonable time frame, these situations are OK from time to time. The team simply does the rewrite with the all the knowledge obtained from writing the existing implementation as well as the new requirements in mind.
| Reference: | Book Excerpt What is a Microservice from our NCG partner Christian Horsdal at the Christian Horsda’s blog blog. |