Last week we discussed the problem of matching string prefixes and designed algorithms on the basis of a sorted list of strings.
Our solutions had good runtimes given the constraint, however we can do much better by using a specialised data structure instead.
The data structure in question is a trie, also called radix tree or prefix tree.
Today we will look at how to construct exactly that.
About tries
For our purposes, a trie is a special kind of tree, where each arc or edge corresponds to a character. Given a collection of strings, our goal is to have each string correspond to one node in the trie, with the characters along the arcs from the root to the node being the characters in the string.
While each leaf of the trie necessarily represents a completed string, even other nodes can contain a string if that string is a valid prefix of any other strings.
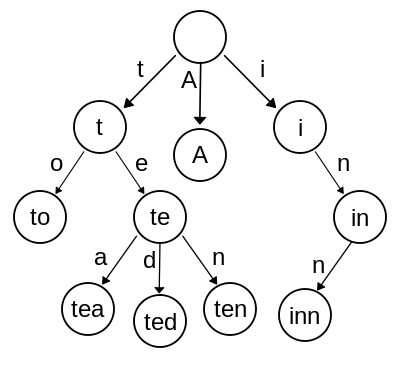
This example trie – shamelessly stolen from Wikipedia – contains the strings “A”, “to”, “tea”, “ted”, “ten”, “i”, “in”, and “inn”.
Constructing a trie
As we can see, each node in our trie can have a number of children, each represented by the character on their corresponding arc. We can represent this in code by storing a dictionary from characters to nodes in each node:
class Node
{
private readonly Dictionary<char, Node> children;
}
Further, observe how each level in the tree corresponds to characters of the same index, i.e. every time we move down a level we move one character to the right in our string.
We will use that fact to construct our trie, starting from the root and building towards the leaves, using a recursive function that advances by one character every time.
To focus on building the trie we will assume that our input is a sorted list of unique non-null strings.
Apart from this list, we also need to keep track of the current character index, and the minimum and maximum index in the string list, corresponding to strings contained in the sub-trie with the current node as root.
The latter are important so that we do not have to enumerate our original list more often than we need to.
Pseudo code
Let us begin by looking at what we are about to implement in pseudo code to get an idea for the algorithm:
node constructor(strings, characterIndex, iMin, iMax)
{
strings2 = strings between iMin and iMax
groups = strings2 grouped by character at characterIndex
foreach (group in groups)
{
this.children.Add(
group character,
new Node(
strings, characterIndex + 1,
startIndex of group,
endIndex of group)
)
}
}
Since our list of strings is sorted, we do not actually need to represent the groups directly. Instead, we can loop over the list from iMin to iMax and create a new group every time the character at the given index changes. This results in the same output, but is much more efficient and takes full advantages of the properties of the sorted list.
We can develop our pseudo code appropriately:
node constructor(strings, characterIndex, iMin, iMax)
{
currentGroupChar = strings[iMin][characterIndex]
for(i = iMin + 1; i < iMax; i++)
{
c = strings[i][characterIndex]
if(c != currentGroupChar)
{
this.children.Add(
currentGroupChar,
new Node(
strings, characterIndex + 1,
iMin,
i)
)
iMin = i
currentGroupChar = c
}
}
this.children.Add(
currentGroupChar,
new Node(
strings, characterIndex + 1,
iMin,
iMax)
)
}
Note how in the end we need to finish the last group as well.
Special cases
This last bit of pseudo code is already very close to what our implementation will look like. Note however, that there are a few important cases that we are missing.
First we need to actually detect when we have reached a leaf. When this happens iMin and iMax are different by only 1, and we can stop the recursion.
Secondly, since not only leaves can contain valid strings, we need in each node if there is a string belonging there. We can do this easily by checking if the length of the string at iMin is equal to the character index. This works because a string is sorted before any string that it is a prefix of. Note how in this case we will also want to increment iMin, since we want to skip the string for consideration for the node’s children.
Implementation
With those two cases discussed, let us implement the Node’s constructor in code.
Node(List<string> strings, int characterIndex, int iMin, int iMax)
{
var s = strings[iMin];
if (s.Length == characterIndex)
{
this.key = s;
iMin++;
}
if (iMin >= iMax)
return;
this.children = new Dictionary<char, Node>();
int characterIndex2 = characterIndex + 1;
char currentGroupChar = strings[iMin][characterIndex];
for (int i = iMin + 1; i < iMax; i++)
{
var c = strings[i][characterIndex];
if (c != currentGroupChar)
{
this.children.Add(currentGroupChar,
new Node(strings, characterIndex2, iMin, i));
iMin = i;
currentGroupChar = c;
}
}
this.children.Add(currentGroupChar,
new Node(strings, characterIndex2, iMin, iMax));
}
Note how I store the string of each node in a key property of the node and how I do not create a dictionary for leaves.
And that is all!
We simply have to pass the right initial data to our root node’s constructor, and the trie will be build. To make things easier on us, let us quickly write a second constructor that simply takes the list and fills in the starting parameters.
public Node(List<string> strings)
: this(strings, 0, 0, strings.Count)
{ }
Conclusion
After our detailed exploration of string prefix matching last week we took a look at prefix-tries and how to construct them today.
Next week we will take a look at the cool things we can do with this representation of our data, as well as analyse the respective runtimes to compare them to a simpler implementation.
Enjoy the pixels!
| Reference: | Matching string prefixes using a prefix-trie from our NCG partner Paul Scharf at the GameDev<T> blog. |