I’m working on a messaging system in .NET. It’s purpose is to allow you to use reliable (and transactional) messaging inside your application without the need of an external server. This post is about the persistence layer (i.e. file storage). It can handle somewhere between 100 000 and 300 000 messages per second depending on the configuration.
The theory
Allow me start by elaborating my thoughts and ideas about how the system could be done. The actual implementation follow later.
Working with files
Those of you that have worked with file operations know that files are just for edits and appends. That is, you can rewrite parts of the file by setting the file position and then invoke fileStream.Write(). To append to a file you simply move to the end of the stream and invoke write.
//edit
fileStream.Position = fileStream.Length - 100;
fileStream.Write(mybuffer, 0, 100);
//append
fileStream.Position = fileStream.Length;
fileStream.Write(mybuffer, 0, 100);
That works great for most applications. But as you know, a queue system is based on FIFO (First in, first out). Adding items to the queue is not a problem, simply append items at the end. Dequeueing items is a whole different story. We have to be able to remove items from the file. If we don’t, we might dequeue the same items when the application is restarted, as the file position is reset.
To solve that we can employ different strategies:
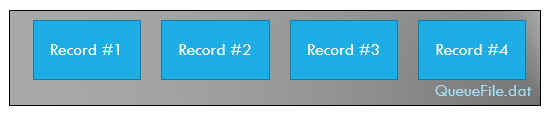
Overwrite file
The first option is to move all contents to the beginning of the file to overwrite the dequeued item (or simply delete the old file and write the rest to a new).
fileStream.Position = 100;
var readBytes = fileStream.Read(hugeBuffer, 0, fileStream.Length - 100);
fileStream.Position = 0;
fileStream.Write(hugeBuffer, 0, readBytes);
However, that would effectively kill the performance due to a large IO overhead.
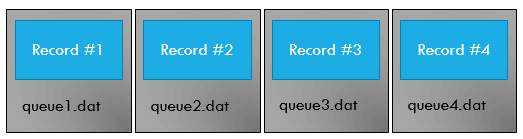
One file per queue
File.WriteAllBytes(fileName, buffer, 0, buffer.length);
This would probably perform a bit better, but still a lot of overhead as we need to manage a lot of files in different locations on the disk. Remember, we want to handle a lot of items per second.
Queueing using files
We have to both accept and embrace the fact that files are append only. So what can we do to use that?
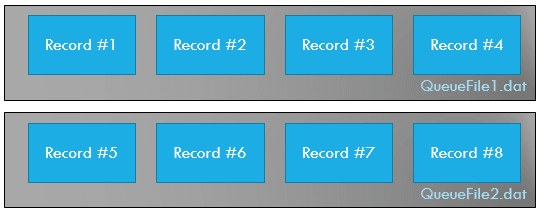
Well. Simply write all queued entries to the same file. The problem with that is that the file will grow indefinitely. To solve that, let’s set a max size for the queue file. Once the size is reached we’ll create a new file.
fileStream.Write(buffer);
if (fileStream.Length > MaxSize)
{
fileStream.Close();
var fileName = string.Format("{0}_{1}.data", _queueName, Guid.NewGuid().ToString("N"));
fileStream = new FileStream(fileName);
}
Reading vs writing
To make it easy, we’ll just use two file streams. One file stream for the writing and one file stream for the reading. By doing so, we do not need to keep track of the file position or move it back and forth. The receive stream will move forward every time we read, and the file stream will continue to append on every write.
So we have these rules now:
Write rules
- Always append to the end of the file
- Once the file size is larger than X bytes, close the file and create a new one
Read rules
- Read next item.
- If EOF, close and delete current file, then open next file
There you go. The write side creates the files and the read side deletes them once done.
Handling restarts
We are seriously screwed if our application crashes or are restarted since the read position is lost. It’s easy to find the correct file to read from, just pick the one with the oldest write time. But the file can contain thousands of queued items and we do not want to dequeue all again. Thus we need to figure out another way to keep track of the file position, even if the application is restarted.
My solution is to use another file that I call “queuefileX.position”. It’s also append only and contains the position that should be read next. Hence we can keep a file stream open to that file to and all we need to write for every dequeue operation is a 4 byte position to the file.
positionFileStream = new FileStream(positionFile);
positionFileStream.Position = positionFileStream.Length - 4;
var bytes = new byte[4];
positionFileStream.Read(bytes);
_dataPosition = BitConverter.ToInt32(bytes, 0);
The position file is created when the read side open a data file and is deleted when all items have been dequeued from the data file.
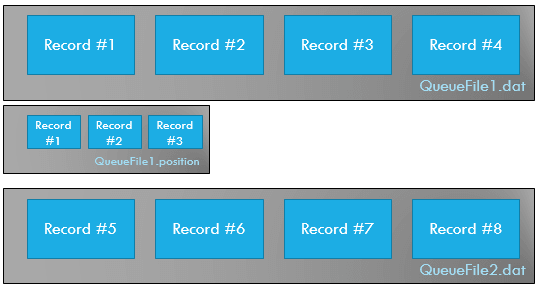
In the image above we’ve read three items from the first file. That’s why there are three records in the position file.
That’s the strategy with dealing with files.
Dealing with disk failures
Disks can break. Heard of bad sectors anyone? If a file goes corrupt we don’t want every record to be lost in that file.
To deal with that the format of the data files are this:
<STX><record size><data>
The STX (ascii 2) indicates the start of the record. So if a record goes corrupt we have to:
- Scan the file forward for the next STX.
- Parse the four next bytes (record size).
- Move forward to next record
- Validate that the position is STX (so that we didn’t find a STX in the record data of the corrupted record)
In that way we hopefully just lose some of the records.
(sure, it’s a rather naive implementation, but at least it’s something).
Increasing performance
I’ve taken a couple of different approaches to gain performance.
Choosing the right reliability technique
Writing to files can be really slow. Especially if you want to make sure that everything is really written to disk and not cached (pending write) inside the operating system.
From what I can gather, you can either use FileOptions.WriteThrough or FileStream.Flush. Both give you a guarantee that everything have been written to disk. At least in .NET 4.5 (bug).
Sequential access
Another thing that really improved performance was to use the FileOptions.SequentialScan flag while reading from the stream. The flag tells the system to optimize file caching (as it knows which bytes are to be read next).
Enqueue multiple items
As I previously stated, it really helps to enqueue several items before flushing.
queue.Enqueue(item1);
queue.Enqueue(item2);
queue.Enqueue(item3);
queue.Enqueue(item4);
queue.FlushWriter();
The same applies to the dequeue side. If you dequeue 100 items directly you only need to write 4 bytes to the position file. If you dequeue one item 100 times you have to write 400 bytes to the file.
The architecture
As we’ve come to conclusion that we have two distinct responsibilities (reading and writing) with their own set of rules, we’ll use that knowledge in the architecture to. Thus having a IPersistantQueueFileWriter and a IPersistantQueueFileReader.
There is one problem though. As the rule for the read side says..
If EOF, close and delete current file, then open next file
.. we’ll have a problem when the read side is faster than the write side. To solve that we need to have a third entity that takes care of the coordination.
My assumption is that there are two different threads doing enqueuing and dequeueing. That’s the IPersistantQueue.
The basic architecture is:
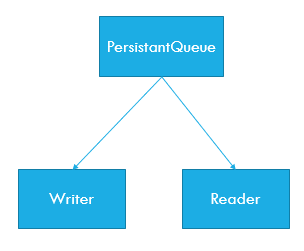
Pretty simple, huh?
A final note is that I decided to use byte[] arrays for all items due to the fact that it doesn’t tie the implementation to a specific serializer and that most messages are reasonable small and therefore easy to handle with byte[] arrays. There is a third class called QueueService which takes care of serialization for you.
Conclusion
That’s how SharpMessaging are dealing with files. Now I just have to create the actual MessageQueue class that ties everything together =)
I’ve created a small test (MeassuredIntegrationTests.cs) that puts 300 000 on a queue and then dequeue them again. Results (on my computer with a SSD):
Enqueue items: 2131ms = 140 778 items/s
Enqueue items (batching): 1496ms = 200 534 items/s
Dequeue items: 2921ms = 205 409 items/s
The items are 2kb large and the max file size was set to 50Mb (2500 items per file).
| Reference: | The persistence layer in SharpMessaging from our NCG partner Jonas Gauffin at the jgauffin’s coding den blog. |